

Según Nielsen, “las soluciones adecuadas podrían ahorrar hasta 1.600 millones de dólares en ingresos perdidos por la pérdida de clientes en un año”.
Introducción
La industria de la conectividad se ha enfrentado a varios desafíos a lo largo de su existencia, uno de los cuales es la pérdida de clientes. La pérdida de clientes se refiere al porcentaje de clientes que cancelan sus suscripciones o cambian a un proveedor de telecomunicaciones diferente dentro de un límite de tiempo específico.
La industria de la conectividad experimenta la tasa de abandono de clientes más alta en comparación con otros sectores. Según un estudio del Grupo Aberdeen, la empresa de telecomunicaciones promedio pierde 100 dólares al mes por cada cliente que abandona. Esto significa que una empresa con una tasa de abandono del 10% podría estar perdiendo 120 millones de dólares al año.
De acuerdo con forrester , una mala experiencia es suficiente para que los clientes consideren cambiar de proveedor. Esto hace necesaria una inversión continua en la predicción de la pérdida de clientes, dado que la retención de clientes es más rentable que la adquisición de clientes. La alta rotación de clientes tiene efectos perjudiciales para el negocio, incluida la pérdida de ingresos, la pérdida de oportunidades de ventas cruzadas y adicionales y dificultades para pronosticar y planificar el crecimiento futuro.
La aparición de técnicas de recopilación de datos y la necesidad de generar conocimientos profundos han llevado a la expansión de las aplicaciones de análisis en varios dominios. Sin embargo, los proveedores de servicios de comunicaciones generan grandes cantidades de datos todos los días, lo que convierte en un desafío importante extraer significado de datos tan complejos y multifacéticos.
El análisis de la pérdida de clientes consume muchos recursos y requiere una gran potencia computacional
A medida que el volumen y el tipo de datos capturados en la industria de la conectividad aumentan exponencialmente, también aumenta la cantidad de métricas y evaluaciones que requieren procesamiento. La predicción y el análisis de la pérdida de clientes generalmente se llevan a cabo mediante modelos ML. Se utilizan numerosos atributos para la investigación, como los datos de facturación, los registros de detalles de llamadas (CDR) y los datos de contrato/suscripción. Por lo tanto, la predicción de la pérdida de clientes requiere una potencia computacional significativa.
Además, la pérdida de clientes es un proceso complejo que involucra múltiples parámetros interdependientes. Por ejemplo, la calidad de la red, que afecta directamente la satisfacción del cliente, puede verse afectada por varios otros factores, como la congestión de la red, la intensidad de la señal y el área de cobertura. Un informe reciente de Gartner predice que los datos generados por las empresas procesados en centros de datos, o la nube, aumentarán al 75% desde el 10% actual para 2025. En otras palabras, se generarán más de 180 zettabytes de datos en todo el mundo a partir de más de 41 mil millones. dispositivos conectados. A medida que se agreguen más parámetros para hacer predicciones precisas, los métodos predictivos actuales se volverán ineficaces a la hora de procesar y analizar datos complejos y multifacéticos, que requieren mucho tiempo, energía y recursos.
Principales desafíos con el enfoque clásico de aprendizaje automático de predicción de abandono
- Examinar conjuntos de datos grandes y diversos para proporcionar soluciones personalizadas es una tarea desafiante que a menudo resulta en un desperdicio de recursos.
- Asignar recursos es un desafío debido al cambio de un entorno de suscriptores centralizado a uno hiper distribuido.
- Analizar y obtener conocimientos a partir de datos multidimensionales es engorroso, lo que genera dificultades para identificar y extraer patrones de abandono complejos
Los proveedores de servicios deben adoptar el aprendizaje automático cuántico para superar las deficiencias del aprendizaje automático clásico, como tiempos de procesamiento más lentos, incapacidad para procesar grandes cantidades de datos en paralelo y baja precisión.
Aprendizaje automático cuántico (QML): un imperativo estratégico para predecir la pérdida de clientes y mantener la ventaja competitiva
Quantum Machine Learning (QML) ofrece un nuevo enfoque para analizar grandes conjuntos de datos y extraer información valiosa para una estimación más rápida de la pérdida de clientes. Puede modelar eficientemente el espacio de características de alta dimensión utilizando paralelismo cuántico. El paralelismo cuántico es una característica de las computadoras cuánticas que les permite realizar múltiples cálculos simultáneamente, explotando la superposición de estados cuánticos para explorar múltiples soluciones a la vez. Al aprovechar el poder de la computación cuántica, puede realizar cálculos rápidos, lo que permite a las empresas analizar los datos de los clientes de manera eficiente y eficaz.
Al utilizar QML, los proveedores de servicios pueden desarrollar modelos predictivos más rápidos para identificar a los clientes que probablemente abandonen. Estos modelos pueden procesar factores como la demografía del cliente, el historial de compras y el comportamiento de navegación, aumentando así la eficiencia a la hora de encontrar clientes en riesgo.
Aquí hay tres escenarios donde QML puede sobresalir:
- Reconocimiento de patrones complejos: la predicción de abandono requiere identificar patrones y dependencias intrincados en los datos, lo cual es difícil para el aprendizaje automático clásico. Quantum ML se puede aprovechar para manejar cálculos complejos y analizar datos de alta dimensión, incluida la frecuencia de las llamadas, el uso de datos, la ubicación y la demografía de los clientes, para descubrir correlaciones ocultas que contribuyen a la deserción.
- Predicción de abandono en tiempo real: prevenir el abandono requiere una acción oportuna y el aprendizaje automático clásico, debido a su tiempo de procesamiento más lento, resulta ineficaz en este sentido. Quantum ML permite la predicción de abandono en tiempo real al proporcionar cálculos y optimizaciones más rápidos. Puede procesar datos rápidamente, lo que permite a los proveedores de servicios identificar clientes potenciales en riesgo y tomar medidas proactivas para retener a los clientes rápidamente.
- Manejo de Big Data: la predicción de abandono a menudo trata con grandes conjuntos de datos que pueden ser computacionalmente intensivos para procesar utilizando métodos de aprendizaje automático clásico. QML puede proporcionar ventajas computacionales para analizar big data aprovechando el paralelismo inherente y los algoritmos cuánticos diseñados para tareas con uso intensivo de datos. Los líderes de marketing de telecomunicaciones pueden utilizar QML para ajustar modelos para predecir la deserción y optimizar parámetros como tasas de aprendizaje y factores de regularización para mejorar la precisión sin una experimentación extensa de prueba y error.
Además, QML podría ayudar a los proveedores de servicios a explorar nuevas posibilidades de análisis de datos y modelos predictivos, lo que podría generar conocimientos precisos a partir de los datos disponibles. Permitirá a los equipos de datos explorar relaciones de datos complejas, mejorar las medidas de seguridad y manejar desafíos de datos importantes.
La siguiente tabla habla sobre un modelo de predicción de abandono de clientes de muestra, destacando las ventajas de Quantum ML sobre el Classical ML en el cálculo de datos altamente complejos e interdependientes.
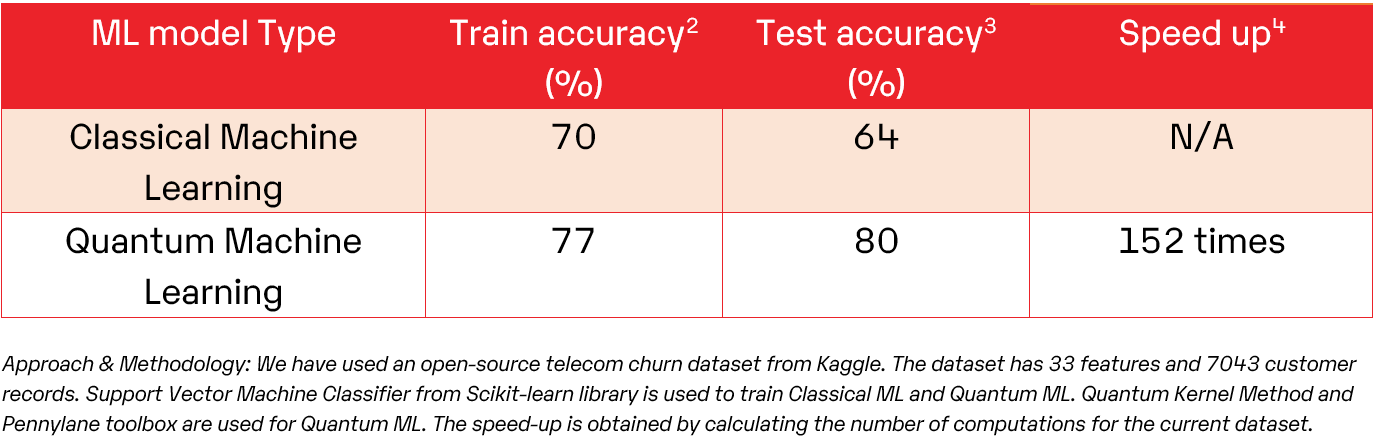
Tabla 1: Comparación de la implementación de Classical ML y Quantum ML de la predicción de abandono de clients.
Una mejora notable en la velocidad general, 152 veces, indica un avance significativo tanto en la eficiencia computacional como en el análisis de conjuntos de datos extensos. Este progreso destaca la rápida evolución de las capacidades QML y subraya el potencial para abordar problemas complejos y obtener conocimientos más rápidamente.
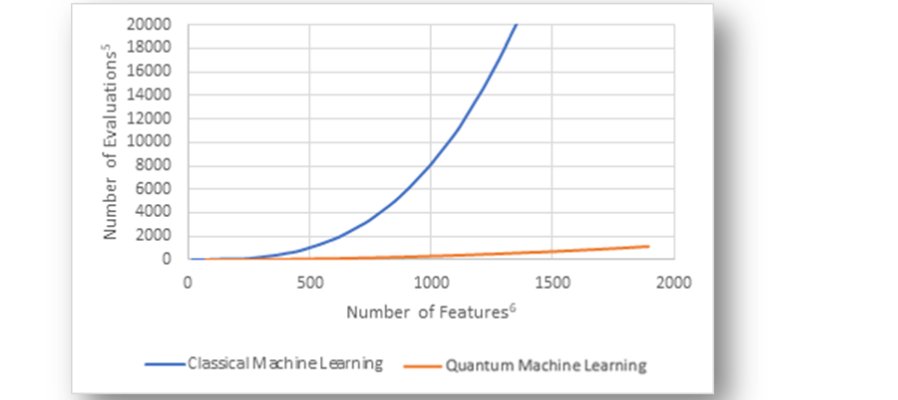
Gráfico 1: Potencial de escalabilidad 7del ML clásico y el ML cuántico
A medida que aumenta la cantidad de parámetros dentro de un conjunto de datos, la implementación de QML reduce significativamente la cantidad total de evaluaciones necesarias para el procesamiento de datos. En el gráfico, a medida que aumenta la cantidad de características/parámetros, la cantidad de evaluaciones aumenta exponencialmente para el ML clásico, lo que significa que se requieren más potencia y recursos computacionales para resolver un problema altamente complejo. Por el contrario, el gráfico es relativamente plano para Quantum ML, lo que indica que será muy eficiente para resolver problemas complejos.
Dada la anticipación generalizada de un aumento del big data en todas las industrias, el aumento en el número de parámetros de predicción es inevitable. Esto hace que la eficiencia de QML sea imperativa para los proveedores de servicios para permitirles ahorrar tiempo e impulsar las capacidades de toma de decisiones.
Conclusión
Quantum ML está cerca de un gran avance en su viaje. Puede reformar completamente el proceso y los modelos de aprendizaje automático, reduciendo el tiempo de procesamiento y mejorando significativamente el rendimiento. Aprovechar QML puede permitir a los proveedores de servicios calcular casos de uso complejos, como la pérdida de clientes, de forma instantánea y precisa, proporcionando beneficios considerables a los proveedores de servicios.