Reduce time taken to fix security vulnerabilities by 50% with vulnerability analysis best practices
Cyber-attacks are increasing every day and are now the third-highest global risk, according to the World Economic Forum. GSMA’s mobile telecommunications security threat landscape report of 2019 says, “there was a 55% increase in breaches caused by open-source software vulnerabilities”.
Addressing security vulnerabilities is a top priority for service providers in the connectedness industry because a cyber-attack could disrupt services for millions of customers, impact customer’s trust, and deteriorate service provider’s brand & reputation. To achieve the required security objectives, service providers must adopt a structured approach to vulnerability management. Vulnerability management, which is the process of finding, assessing, remediating, and mitigating security weaknesses for known assets, gives service providers the ability to assess the status and risk of unknown hardware/software.
Depending on the service provider’s infrastructure size and state of the configuration management database (CMDB), finding the responsible asset owner can be a highly challenging and cumbersome task, resulting in lead times of up to many weeks. Therefore, vulnerability management must include automation to discover new vulnerabilities, perform risk assessment, and assign it to the right team for a quick resolution.
Addressing security vulnerabilities with speed is a top priority for service providers as a successful cyber-attack can essentially disrupt service for millions of customers
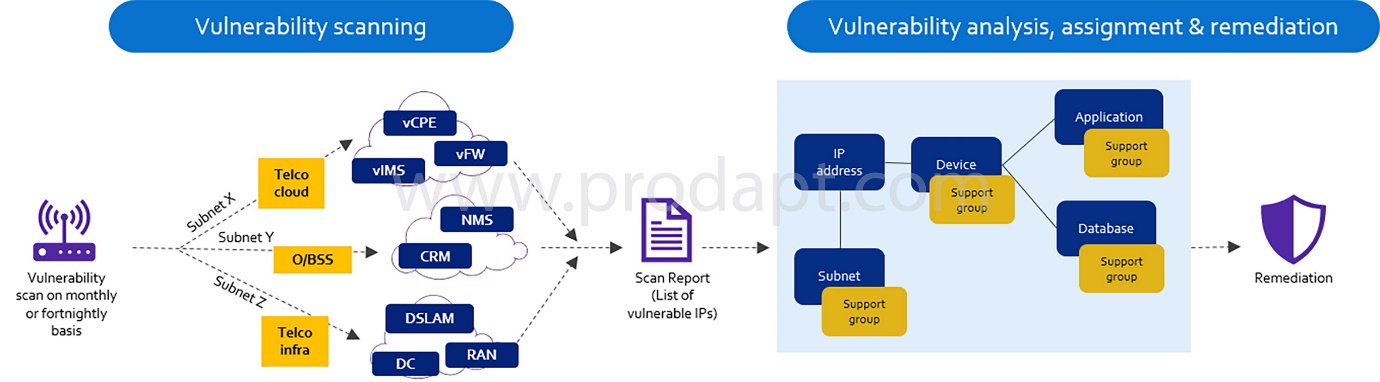
Fig: Steps followed in field service operation showcasing the importance of spare information